


Petrosys Intelligent Search
Kevin Ward, VP Petrosys Europe, Russia & Africa
Petrosys were pleased to be invited to present the paper, ‘Can Elasticsearch help us access large Oil & Gas datasets more efficiently?’ at the recent Society of Petroleum Data Management (SPDM) virtual conference.
A few months ago, our development team were given time to spend on ‘creative innovation’, with the opportunity to work freely on a project of their choice that they felt would offer the most value to our clients. Prompted by some ongoing work with a few clients – we have been using Elasticsearch to overcome the challenges when trying to make sense of decades worth of unstructured reports, documents, and generic files, in an effort to get the data easily into the hands of subsurface technical teams – Data Management Product Manager Brad Rymer decided to investigate different ways of loading data from multiple sources, further evaluating the capabilities of Elasticsearch.
The world’s leading open-source search and analytics solution, Elasticsearch, could help improve the performance and intelligence of Petrosys’s current ability to find, categorise and visualise unstructured data on oil and gas datasets. Delivered at the SPDM conference by Paul Gibb, Petrosys Business Development Manager, we think it made for an insightful presentation.
What is Elasticsearch?
Let’s start off by briefly introducing what Elasticsearch is for those who haven’t heard of it. If you go to their website – https://www.elastic.co/ you’ll see, Elasticsearch helps all industries explore and analyze very large datasets. Elasticsearch is not a replacement for SQL Server or Oracle, it’s a complementary tool specifically designed to do fast searches of large datasets, be it structured or unstructured text, numerical data, or geospatial data.
Without the traditional burdens of relational databases, Elasticsearch is fast and scalable – running on a single server or across multiple machines on multiple nodes to solve large data management challenges.
In summary, Elasticsearch won’t be able to do everything to overcome the challenge, but it will improve the performance and efficiency of working with the large datasets involved.
The problem – Where is all the data?
Petrosys has already developed a crawler to find data, turn it into a series of records, map data types to an object, and extract the content of the files. However, before we look at how Elasticsearch has made this process more ‘intelligent’, let’s go through the problem we’re trying to address and the methods currently being used to solve the issue.
Following many years, decades, of interpretation and analysis, with IT system upgrades, evolving file formats, increased capacity to store more information, mergers and restructuring; we now have unmanageable volumes of data in our industry and there is a risk of critical knowledge being isolated or lost forever.
The challenge for data managers, geoscientists, and engineers is:
- to be able to quickly find trusted information
- to better understand what data exists and is available
- to know if we have duplicates that we can remove to help improve the data resource
- to implement a system that does all of the above while reducing the need for people to manually review each record
Managing unstructured data, such as well reports, seismic data acquisition, and processing documentation, in-house or external evaluations, and analysis, commercial reports, presentations, can present a sizeable challenge. Exploration teams can hold tens of millions of files of various formats, in many different folders where ownership and access is complex.
A significant proportion of the data comprises duplicates or working and final versions and the creator/owner of the data may have long since left the company.
For example, imagine you are evaluating a prospect near to the ‘Parara-1’ well which was a successful exploration well. Parara-1 was drilled 15 years ago and over those 15 years, your company has accumulated well reports in Word format, geological presentations in Powerpoint, production data in Excel, and core photographs and reports in PNG and PDF formats (i.e. in a variety of ‘unstructured data’ formats). Parara-1 has also been referenced in many other more regional geological reports which discuss why this well was successful and how this relates to the prospectivity of the region.
Some of the reports are on your ‘go to’ share drive. Some are in paper copies with important geological sketches. Some are in user folders. Some are in file systems used by engineers. Some are on older file systems that are no longer used.
You cannot go and ask the team who planned well Parara-1 because they no longer work at your company. In summary, you have a lot of data about the Parara-1 well that you need access to if you’re going to fully understand how risky/lucrative your prospect is but you have no idea where it all is, if you’ve managed to find it all or if you’re looking at the latest version of each file.
The Solution – Petrosys Intelligent Search
As mentioned, Petrosys has already developed a solution that finds, categorises, and visualises unstructured data. With the addition of Elasticsearch within this cataloguing workflow, shown below in Figure 1, the solution is now being referred to as ‘Petrosys Intelligent Search’. The purpose of Petrosys Intelligent Search is to derive better search results from the various data sources and to see a breakdown of document types.
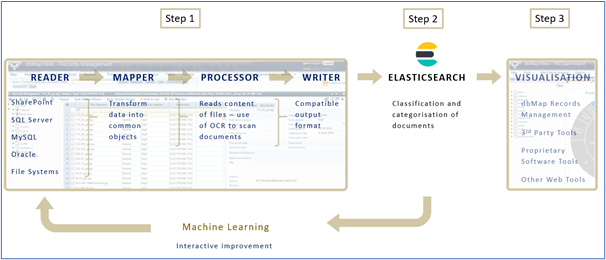
Figure 1: An overview of the 3 steps of the Petrosys Intelligent Search
Step 1:
- read data from various sources
- transform the data into common objects, over which you scan the content (using Optical Character Recognition if required)
- convert the data into a compatible output format for Elasticsearch
Step 2:
- Elasticsearch is then used to work through the data provided and begin the classification and categorisation of documents. At this stage, Data Managers work to improve the data model so that subsequent iterations of the workflow improve the classification and categorisation results. “Elasticsearch is where the indexing, search, and analysis magic happens.”
Step 3,
- (often run concurrently with step two) the results of the classification and categorisation of the data can be viewed in the Petrosys Records Management tool and can help inform the continuing development of the data model.
The ‘Intelligent’ part
As a geoscientist, the whole process seems very intelligent to me, but the part of the process that I find particularly powerful is the ‘Machine Learning’ process where the model is continually learning and improving with each iteration. To show this visually, have a look at Figure 2.
Here, we have manually identified a small subset of documents (e.g. well production reports) which represent a good example of particular data types. With these templates identified, a batch of ~150,000 unclassified documents is loaded into the Petrosys Intelligent Search. The documents which the model deems to be similar to the original subset, are classified.
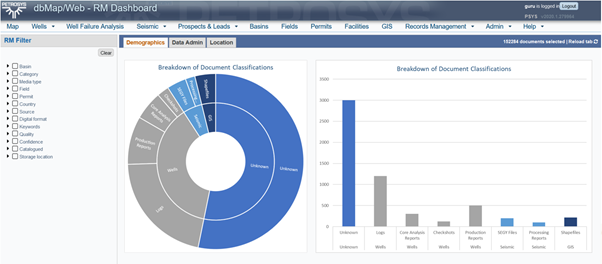
Figure 2: An example of the first iterative search through a dataset
However, as Figure 2 shows, there are still over 50% of the ~150,000 documents that are not classified and even those which are classified are only broken down into a few sub-categories.
Therefore, we need to update and refresh the model before loading the next batch of unclassified documents. These results are shown in Figure 3.
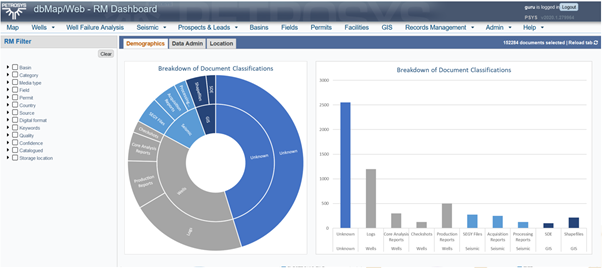
Figure 3: An example of the second iterative search through a dataset
There is now a wider mix of GIS and Seismic data classified and more than 50% of all documents have been categorised.
This iterative updating and improvement of the model continues until the model meets its goals and/or all the files are loaded. Figure 4 shows a further iteration in the model.
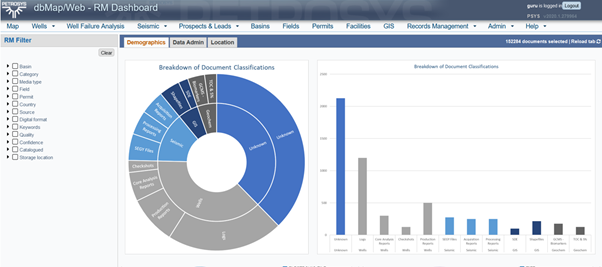
Figure 4: An example of the third iterative search through a dataset
Now, if I’m a geoscientist looking for files related to the ‘Parara-1’ well, I could go to my visualising tool and find the data I need to get my hands on. In the example below (see Figure 5) we have used the Petrosys Records Management module to find and access the data.
The simple process for the end technical user is:
- Search for the name of the well (either in the title or within the document)
- View/select which category of document you are interested in
- Add 1 or more files to the download ‘cart’
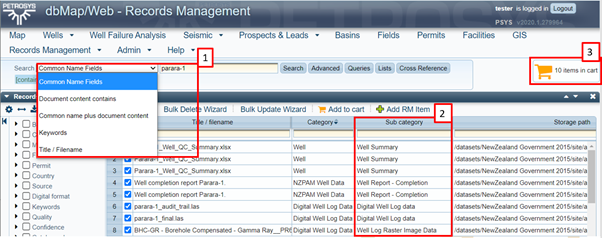
Figure 5: The Petrosys Records Management (RM) module showing how an end user may find and access the required documents
Seems intelligent to me but I’d be very interested to hear what you think.